
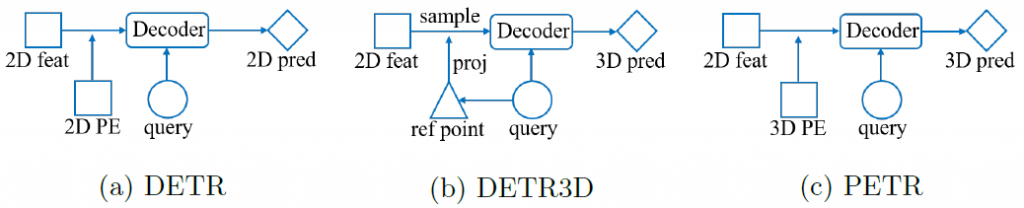
petr模型的架构与detr模型基本一致,整体简洁优雅,避免了detr3d的一些较为复杂的流程。
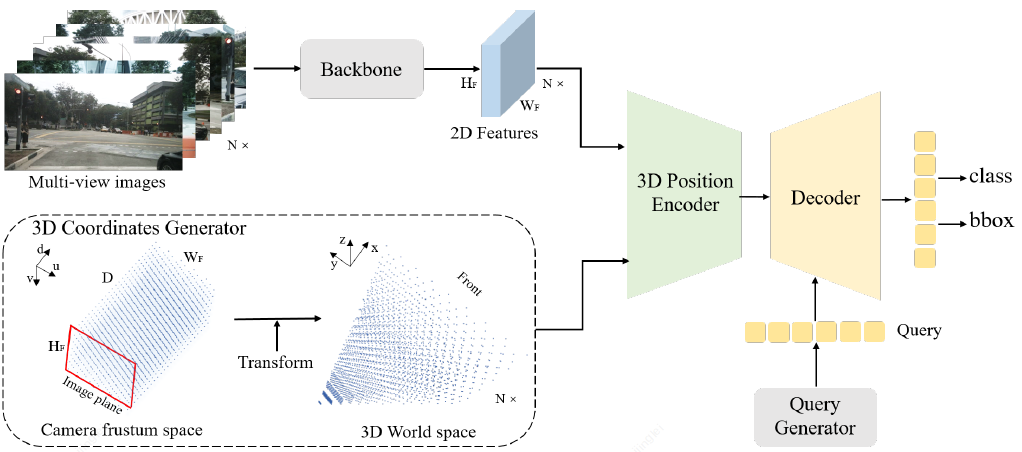
petr模型首先是使用如resnet、vovnet等backbone提取图像2d特征,然后与生成的3d坐标一起进入encoder,encoder的结果与object query一起进入decoder,decoder的输出经过分类和回归的head得到bbox。
3d 坐标的生成:将图像坐标系空间,分成尺寸为(Wf, Hf, D)的meshgrid,meshgrid的点的坐标可以表示为(u × d, v × d, d)。meshgrid经过与相机内外侧得到的矩阵相乘,投影到3d世界坐标系,将在世界坐标系下的meshgrid的点,根据检测的roi区域进行归一化。就是生成的3d坐标。
3D position encoder,将3d坐标,经过一个mlp,得到position embedding,与2d feature经过一个1×1卷积后相加,得到3d position-aware feature。
3d object query:petr是初始化了在3d坐标系下从0到1均匀分布的可学习的一组anchor points,然后anchor points的坐标经过一个mlp,得到object query。然后训练时会更新这些anchor points