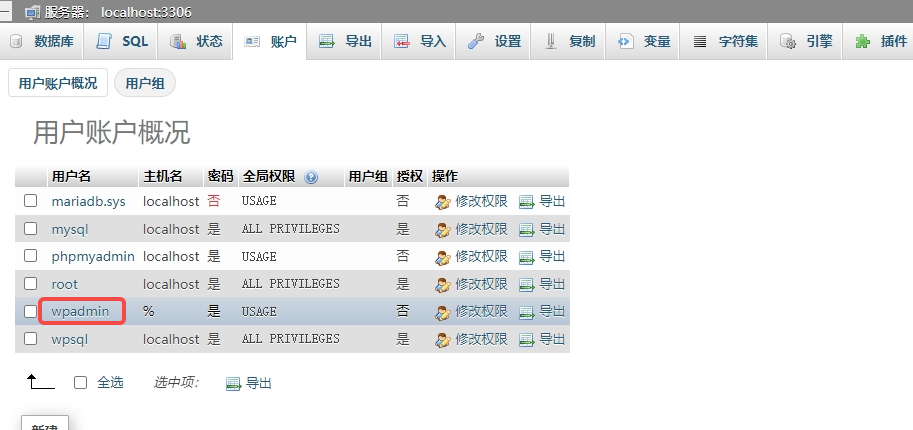
传统mesh渲染过程的不可微分性
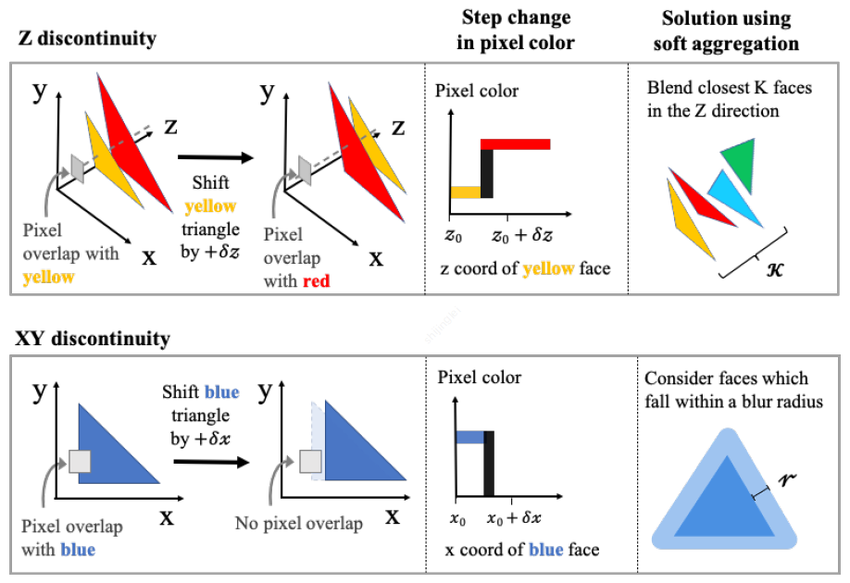
传统的mesh渲染算法,计算某个像素值,是根据通过像素的光线与mesh模型相交的face确定的。而这个过程是离散的过程,如下图所示。在z方向,face沿着z方向的移动会造成像素值跳变;在xy方向,face沿着xy方向移动也会造成像素值跳变。因此像素值与face的空间位置之间的函数是一个不可微的函数,也就无法通过像素值的差异来反向传播更新face的空间位置。pytorch3d采用了一种可微分渲染的方式,实现了像素值和face之间的可微分的函数。
pytorch3d Renderer
pytorch3d实现了对于mesh可微分的渲染过程:pytorch3d中的渲染器Renderer包含两个主要的部分,rasterizer和shader。rasterizer负责将mesh模型进行光栅化,作用是将mesh的face对应到2d图像像素;shader负责对像素进行着色。pytorch3d的可微分渲染主要参照论文《Soft Rasterizer: Differentiable Rendering for Unsupervised Single-View Mesh Reconstruction》,并进行了改动以提升计算效率。
Soft Rasterizer
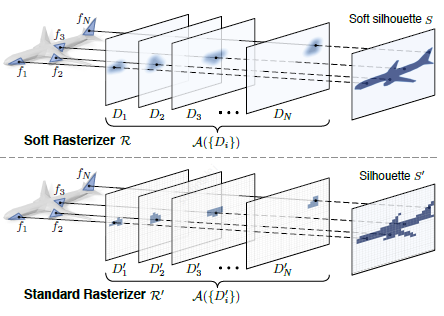
传统的rasterizer将mesh模型映射到2d图像像素,是一个离散的过程。由通过像素的光线与mesh模型相交的face确定。soft rasterizer的假设是,对一个像素来说,每个face对该像素都有某种程度影响,将所有face对该像素的影响进行一种综合,就确定了该像素最终的结果。
计算face对像素的影响程度
对于第i个像素,第j个face对其的影响程度D定义为
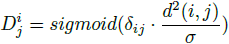
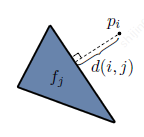
其中,d(i, j)为像素i到face j的边缘的最小距离。
δ为符号系数,表示像素在face内部还是外部
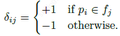
σ为超参数,控制距离对于D的影响大小。
sigmoid函数将这个值限制到0-1之间,并且像素在face内部时,D大于0.5,在face外部时小于0.5。
从这个定义来看,D关于face的位置是可微的。
聚合函数
Soft rasterizer论文是要计算mesh的silhouette,相当于在图像平面的影子或者mask。
对于第i个像素,将所有face对它的影响用一种方式聚合,作为该像素最终的结果。soft rasterizer定义的聚合函数如下:
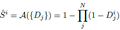
其中,j表示第j个face,N为face的总数。这个定义,使得只要有1个face对该像素的影响是1,那该像素最终的结果就是1。当所有的face对该像素的影响都是0时,该像素的结果才为0。
这个聚合函数也是一个可微的函数。因此,最终像素的结果关于face的位置是一个可微的函数。
pytorch3d的改动
pytorch3d对上面的过程进行了一些修改,以符合计算效率和模块化的要求。
pytorch3d中的rasterizer
首先,soft rasterizer中,一个像素的结果是由所有的face来计算确定的,而这存在很大的计算浪费,因为大多数face和该像素是相隔很远的,影响程度为0。所以pytorch3d是选择沿着z轴最近的k个face来计算。
另外,soft rasterizer将rasterization和shading写到一个cuda核函数中,pytorch3d将它们进行了解耦。rasterizer返回每个像素的k个最近的face的信息,包括face索引,像素在face中的重心坐标,以及像素到face分别在z方向和xy平面方向的距离(带符号)。shader利用这些信息进行着色。这样用户可以自定义shader。
pytorch3d中的shader
shader一般就是根据像素对应的face采用某种方式进行融合。pytorch3d中两种shader算法如下,

算法1计算silhouette,也就是soft rasterizer论文中的聚合函数,dists就是soft rasterizer论文中计算的D。

算法2计算rgb值,这也是RoMe中使用的shader。