transformer最开始是做翻译的,之前看它的论文以及网上相关介绍,对一些东西没有弄明白,看了知乎的一个介绍 Transformer模型详解(图解最完整版) – 知乎 (zhihu.com) ,然后研究了一下GitHub上的代码 GitHub – jadore801120/attention-is-all-you-need-pytorch: A PyTorch implementation of the Transformer model in “Attention is All You Need”. ,算是基本把原本transformer弄懂了。在此总结一下之前没有弄明白的几个问题。
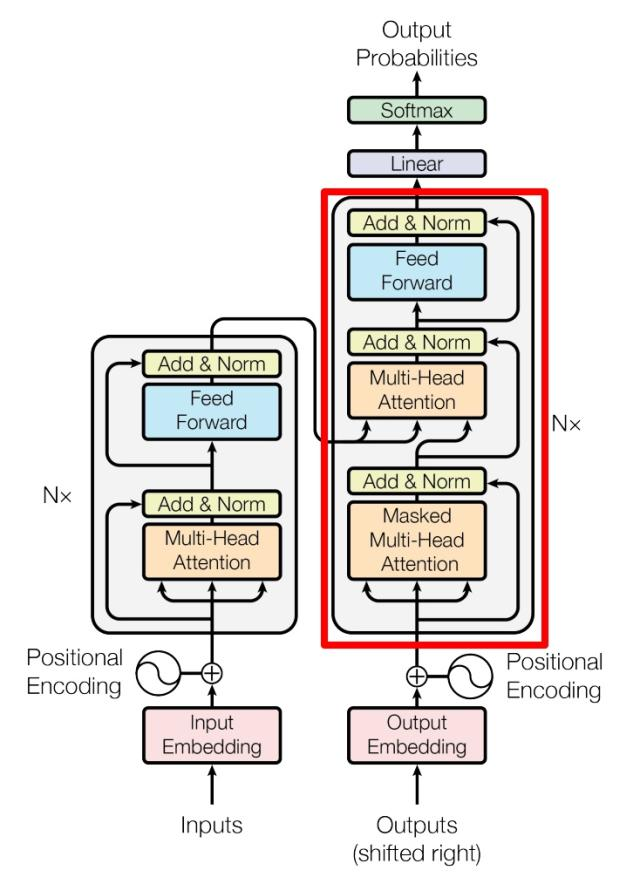
transformer总体结构 从上面的总体架构看,其实涵盖了网络的核心部分,但是有一些地方没有详细说明,也是给我造成了一些疑问,然后研究了一下代码才搞懂。首先从输入开始说明。输入是一段话,预处理就是将每个词根据词汇表映射成一个整数来表示它,我理解就是这个词的token,然后输入到网络里的就是这一串整数。网络将这串数字,首先经过torch.nn.embedding层,得到输入的embedding。
然后就是加上position_encoding,经过encoder。图中灰色的部分就是encoder_layer。encoder是n个不同的encoder_layer组成,而不是一个encoder_layer重复n次。右边的decoder也是同理。
然后就到decoder的部分。一开始会有一个初始的token,表示句子的开始,同样也是经过torch.nn.Embedding层得到embedding,然后经过decoder(需要encoder的输出),得到最后decoder的output,然后这个output经过linear层和softmax,得到一个结果,但是这里注意,这个结果并不是最后的结果,句子已经翻译完了,而只是得到下一个token,softmax输出表示下一个token的可能性。然后取可能性最大的作为预测的下一个token,将预测的token,接在之前的所有token后面,再次重复decoder的过程,直到某一个预测的token为表示句子结束的token。最后将得到的token序列,根据词汇表映射为对应的单词,完成句子的翻译。因此,翻译结果中每个单词是逐个得到而不是一次性完成的,每一个输出的单词都是由已经得到的结果,经过一次decoder得到的。
而decoder最后经过softmax得到下一个token,并不总是直接取可能性最大的token作为结果。实际上transformer维护着k个可能性最高的token序列以及它们对应的可能性得分。将这k个序列都输入decoder ,并每个仍然记录k个可能性最高的预测token,这样得到k^2的一个概率矩阵(矩阵每个元素是预测的token可能性与输入token序列的可能性相乘)。取矩阵中k个可能性最高的结果,更新维护的序列(由这些结果对应的原序列和预测token组成)及其对应的可能性得分(这些结果对应在矩阵中的概率)。
transformer预测的时候基本就是这样,然后之前还有一点没搞懂的就是它在decoder时候的mask操作。实际上在预测的时候,mask没有发挥作用,或者说mask全部没有遮挡。是在训练的时候用到的mask。前文说了,预测的时候是输入已经得到的结果序列,然后预测下一个token。但是在训练的时候,并不是每次都只输入一个不完整的序列,然后让它预测下一个token,再与对应的目标token来计算loss。而实际上是输入开始token+整个句子,目标序列是整个句子+结束token。训练时把整个输入序列都输入到decoder中,但是预测的时候输入的是不完整的序列,这里就存在差异,所以在这时候mask就派上用场了。在decoder的masked attention那里,用一个mask矩阵(下三角部分不遮挡,上三角部分遮挡)与计算得到的attention矩阵点乘,这样使得经过masked MHA之后输出的序列Z(和输入序列长度相同),每个位置的结果都只是由输入序列该位置之前的内容计算得到的,就等同于对Z的这个位置元素来说,输入就是从开头到这个位置的不完整序列。最后decoder的输出也是同理,每个位置的结果都只从输入序列该位置之前的内容计算得到。再经过linear(linear之后长度仍然和输入的长度一致)和softmax,取每个位置softmax后的结果,与该位置对应的目标token,计算loss,实现训练。(预测的时候是取最后一个位置对应的softmax的结果作为预测,前面位置的结果是无意义的)