
命令行进到项目根目录
运行:pipreqs ./ –encoding=utf-8
然后就会看到这个项目所有以来环境的requirements.txt了
信息论基础学习二(条件熵、互信息)
联合熵(joint entropy)
联合熵等于由联合事件发生概率计算出的熵。
\[H(X, Y) = E_{X,Y}[-{\rm log}p(x,y)] = -\sum_{x,y}p(x,y){\rm log}p(x,y)\]
条件熵(conditional entropy)
系统有个随机变量X,Y,当给定条件Y=y时,p(X|Y=y)的熵为
\[{\rm H}(X|Y=y) = {\rm H}_{[X|Y]}[-{\rm log}P(x|y)] = -\sum_{x∈X}p(x|y){\rm log}p(x|y)\]
条件熵定义为上面的熵对Y分布的期望
\[{\rm H}(X) = {\rm E}_{Y}{\rm H}[(X|y)] = -\sum_{y∈Y}p(y)\sum_{x∈X}p(x|y){\rm log}p(x|y) = \sum_{x,y}p(x,y){\rm log}\frac{p(y)}{p(x,y)} \]
条件熵的含义为:如果知道了Y,X的熵是多少。注意与“知道Y等于一个具体的y后,X的熵”,这两种表述的区分。前者是后者在Y上的总体情况。
条件熵的另一种解读为,知道了Y之后,X的不确定性是多少。 将条件熵变形为:
\[H(X|Y) = H(X, Y) – H(Y)\]
可以理解为:“X、Y都不知道时的不确定性”减去“Y的不确定性”等于“知道Y后X的不确定性”。
互信息(mutual information)
首先了解pointwise mutual information,它的定义为:
\[{\rm pmi}(x;y) = {\rm log}_{2}\frac{p(x,y)}{p(x)p(y)} = {\rm log}_{2}\frac{p(x|y)}{p(x)} = {\rm log}_{2}\frac{p(y|x)}{p(y)} \]
含义为比较两个结果同时发生的概率与两个结果各自发生概率的乘积(即假设两个事件独立,它们同时发生的概率)。pointwise互信息具有对称性。当其为0时表示两个结果是独立的。当其大于0,表示两个结果有正向关联,即一个发生会导致另一个更容易发生。小于0时表示有负向关联,一个发生会导致另一个更不容易发生。它的上下界为:
\[-\infty ≤ {\rm pmi}(x;y) ≤ {\rm min} [-{\rm log}p(x), -{\rm log}p(y)]\]
互信息是pointwise 互信息在所有结果上的期望
\[I(X;Y) = E_{X,Y}[SI(x,y)] = \sum_{x,y}p(x,y){\rm log}\frac{p(x,y)}{p(x)p(y)}\]
从定义的形式上可以看出,互信息还是P(X, Y)和P(X)*P(Y)的KL散度
\[I(X;Y) = KL(P_{(X,Y)}||P(X)\cdot P(Y))\]
互信息本质上描述了X和Y的相关性。表示通过知道一个变量的结果,可以减少的关于另一个变量的不确定性。如果两个变量完全独立,那么互信息为0,知道一个变量对于另一变量的不确定性完全没有帮助。如果两个变量完全相关,即一个变量完全决定了另一个变量,那么互信息就是其中一个变量的熵。
互信息具有对称性;但与point mutual information不同,互信息具有非负性。
变形式
\[\begin{split}
{\rm I}(X;Y) &= {\rm H}(X) – {\rm H}(X|Y)
\\ &= {\rm H}(Y) – {\rm H}(Y|X)
\\ &= {\rm H}(X) + {\rm H}(Y) – {\rm H}(X,Y)
\\ &= {\rm H}(X,Y) – {\rm H}(X|Y) – {\rm H}(Y|X)
\end{split}\]
从前两个等式可以直观看出,互信息表示知道一个变量的结果,减少的关于另一个变量的不确定性。
信息论基础学习(一)
信息量
如果现在知道了一个随机事件的结果,那么如何衡量知道这个结果所带来的信息呢?或者说知道了这个结果,相较于不知道这个结果,所减少的不确定性是多少?shannon针对这个问题给出了事件m的信息量的定义:
$$ I(m) = log(\frac{1}{p(m)}) = -log(p(m)) $$
其中,\( p(m) \) 是m发生的概率,log以2为底的话,计算结果以shannon为单位,或者是更通用的bit为单位。 为什么定义成这种形式,因为需要信息量满足以下两个条件:1、事件结果发生概率越大,信息量越少,即事件结果的信息量与其发生概率呈负相关。2、多个事件结果同时发生的信息量,等于其中每个事件结果信息量之和。 从该定义可以得到,发生概率越低的事件,带来的信息量越大。反之则越小。这也符合常规的认知。比如知道明天的天气是晴天,那么给我们带来的信息量则不是太大,因为晴天很常见。但是如果知道明天会有龙卷风,那么则带来了很大的信息量,因为龙卷风是很罕见的天气。从另一个角度去理解,定义的一个事件的信息量表示这个事件会带来的“惊讶度”(surprise)。
熵
表示一个随机事件所有结果的信息量的期望。或者说在只知道所有结果的概率分布时,整个系统的不确定性。 \[ {\rm H}(M) = {\rm E}[{\rm I}(M)] = \sum_{m∈M}p(m){\rm I}(m) = -\sum_{m∈M}p(m){\rm log}p(m) \]
一个随机系统的熵,在各个结果的概率相等时,是最大的。这时系统的随机性也是最大的。而如果这个随机系统只会有一个确定的结果,那么熵为0,系统是确定的没有随机性。在物理中,熵的概念是表示一个系统混乱的程度,与信息论中的熵有着相同的内涵。从另一个角度理解,熵也可以理解成系统混乱性的衡量。
KL散度
表示两个分布之间的差异程度的量化,也就是这个两个分布的“距离”。(实际上不能直接当成距离,因为不满足对称性,即\( KL(p||q) ≠ KL(q||p) \),而且不能满足三角形两边之和一定大于第三边的条件,即\( KL(p||r) + KL(r||q) \) 一定大于\( KL(p||q)) \)
\[ KL(p(X)||q(X)) = \sum_{x∈X}-p(x){\rm log}q(x) – \sum_{x∈X}-p(x){\rm log}p(x) = \sum_{x∈X}p(x){\rm log}\frac{p(x)}{q(x)} \]
当两个分布完全相同时,KL散度为0。 在深度学习中,KL散度常用来作为两个分布之间差异的衡量,对于一个确定的分布\(p\),通过KL散度衡量一个估计的分布\(q\)和\(p\)之间的差异\(KL(p||q)\)。通过减少KL散度来使\(q\)和\(p\)之间的差异。
维基百科上对KL散度的另一种解读: Another interpretation of the KL divergence is the “unnecessary surprise” introduced by a prior from the truth: suppose a number X is about to be drawn randomly from a discrete set with probability distribution \(p(x)\). If Alice knows the true distribution \(p(x)\), while Bob believes (has a prior) that the distribution is \(q(x)\), then Bob will be more surprised than Alice, on average, upon seeing the value of X. The KL divergence is the (objective) expected value of Bob’s (subjective) surprisal minus Alice’s surprisal, measured in bits if the log is in base 2. In this way, the extent to which Bob’s prior is “wrong” can be quantified in terms of how “unnecessarily surprised” it is expected to make him.
交叉熵与KL 散度
交叉熵常作为分类任务的损失函数,但是来源是什么。其实本质上,减少交叉熵损失,其实是降低预测分布与GT分布之间的KL散度,从而让预测分布与GT分布接近。
\[ \begin{split} KL(p||q) &= – \sum_{k}p_{k}{\rm log}\frac{q_{k}}{p_{k}} \\ &= -\sum_{k}p_{k}{\rm log}q_{k} – ( – \sum_{k}p_{k}{\rm log}p_{k}) \\ &= {\rm H}(p, q) – {\rm H}(p) \end{split} \]
其中\(p\)为GT的分布,\(q\)为预测分布。\({\rm H}(p, q)\)就是交叉熵, \({\rm H} (p)\)是\(p\)的熵。因为GT分布是确定的,所以 \({\rm H} (p)\) 这一项是一个定值,与求 \(q\) 是无关的。因此,减少交叉熵损失,其实就是在降低预测分布与GT分布之间的KL散度。
最小化KL散度等价于最大化似然函数
对于一个未知的\(p(x)\),可以通过\(q(x|θ)\)来近似 \(p(x)\) , \(q(x|θ)\) 由可调节的参数\(θ\)控制(比如神经网络中的权重)。通过最小化\({\rm KL}(p(x)|q(x|θ))\)来确定 \(q(x|θ)\) 。但是计算这个KL散度又要求知道 \(p(x)\) ,这成了一个循环的问题。重新审视KL散度,它也可以理解成\(log( p(x) / q(x|θ) )\)关于 \(p(x)\) 的期望,而求期望则可以通过蒙特卡洛估计的方式进行,在实际中就是采样若干的数据,用这些数据计算\(log(p(x) / q(x|θ))\)的平均值来作为其期望。写成公式为:
\[KL(p||q) ≈ \frac{1}{N}\sum_{n=1}^{N}[-{\rm ln}q(x_{n}|\theta) + {\rm ln}p(x_{n})]\]
式中右边第二项与\(θ\)无关,优化时可以直接省略。而第一项就是采样数据的负对数似然函数,同时也是训练分类网络用的交叉熵函数。因此,最小化KL散度等价于最大化似然函数。
tmux使用
新建会话:tmux new -s session-name
查看会话:tmux ls
进入会话:tmux a -t session-name
断开会话:tmux detach
关闭会话:tmux kill-session -t session-name
numba 操作pytorch GPU tensor
numba可以对numpy的array使用gpu进行并行计算,从而进行加速。
import numpy as np
from numba import cuda
自定义numba cuda函数
@cuda.jit
def mat_add(A, B, C):
j, i = cuda.grid(2)
C[i, j] = A[i, j] + B[i, j]
a = np.arange(12).reshape(3, 4)
b = np.arange(12, 24).reshape(3, 4)
c = cuda.device_array_like(a_in)
a_dev = cuda.to_device(a)
b_dev = cuda.to_device(b)
blocks = (1, 1)
threads_per_block = (4, 3)
mat_add[blocks, threads_per_block](a_dev, b_dev, c)
print(c.copy_to_host())
其它
stride_j, stride_i = cuda.gridsize(2) 使用共享内存 tmp = cuda.shared.array((32, 32), numba.types.int32) 对共享内存的读写要注意进行同步 cuda.syncthreads()
pytorch现在提供给numba一个接口,可以使用numba直接对pytorch的gpu tensor进行操作,从而可以比较方便地实现自己想要的一些运算。
import torch import numba.cuda a = torch.arange(12).reshape(3,4).cuda() a_nb = numba.cuda.as_cuda_array(a) # 这里a_nb和a的数据是同一片内存空间的,因此a_nb对数据修改,a的数据也会同样修改,反之亦然。 # 得到a_nb后,就可以用自定义的并行运算函数进行操作了
ndk-stack
ndk-stack从报错的堆栈信息中可以得到错误对应的源文件和行号。该工具在ndk安装目录下prebuil/windows-x86_64/bin下。首先将报错堆栈信息保存为error.log文件。然后执行
.\ndk-stack.exe -sym 工程所在目录\build\intermediates\cmake\debug\obj\armeabi-v7a\ -dump error.log
即可得到错误对应的源文件和行号
安装cuda 10.1及cuDNN
https://www.cnblogs.com/zongfa/p/13947071.html
我安装的显卡的驱动版本是455,使用nvidia-smi看到该驱动支持的最高cuda版本为11.1,因此可以安装cuda10.1
Ubuntu20.04自带的gcc版本为9.3,而cuda10.1不支持gcc-9,因此要手动安装gcc-7,命令如下:
sudo apt-get install gcc-7 g++-7
安装完gcc-7,系统中就存在两个版本的gcc(g++),因此要设置默认的gcc和g++,命令如下:
sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-7 9
sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-9 1sudo update-alternatives --install /usr/bin/g++ g++ /usr/bin/g++-7 9
sudo update-alternatives --install /usr/bin/g++ g++ /usr/bin/g++-9 1显示g++优先级:
sudo update-alternatives --display g++去官网下载cuda10.1的安装文件 cuda下载。使用run文件安装(使用deb文件会自动安装显卡驱动)
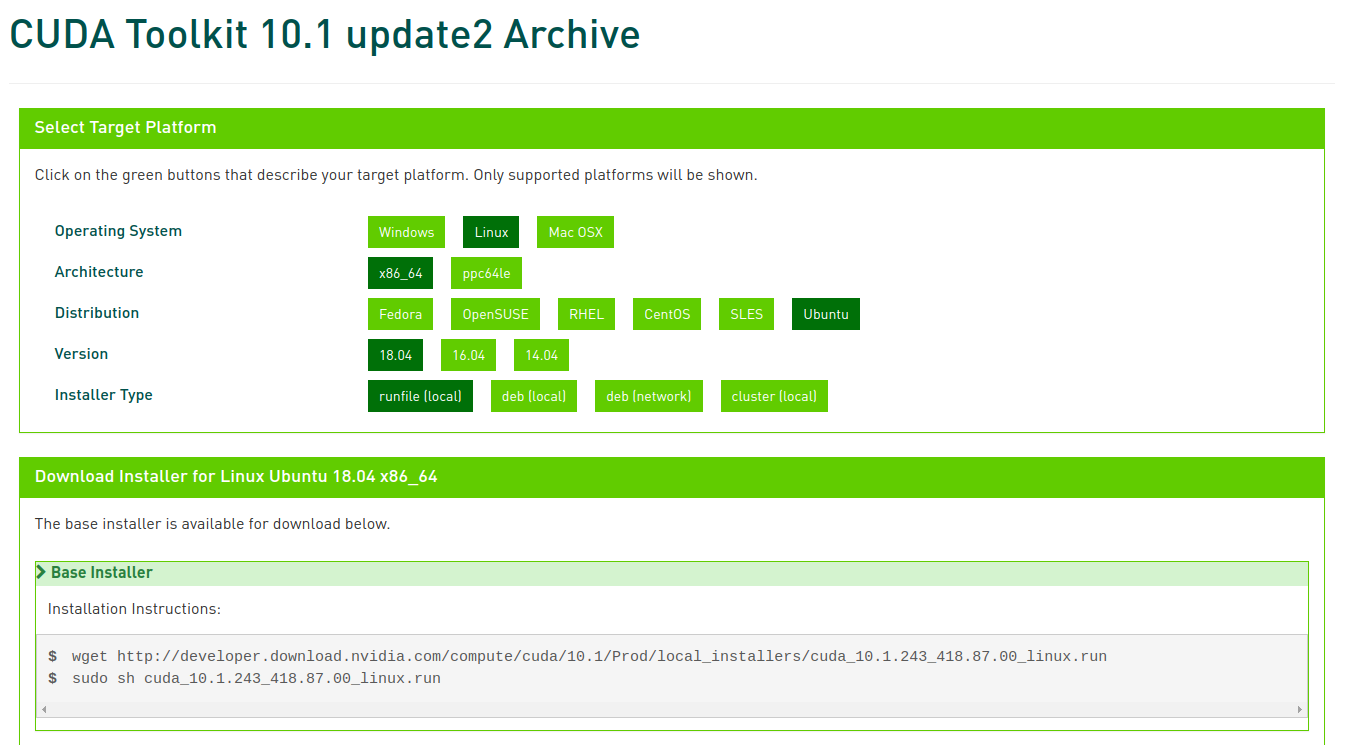
安装界面启动,直接选择continue,然后accept。
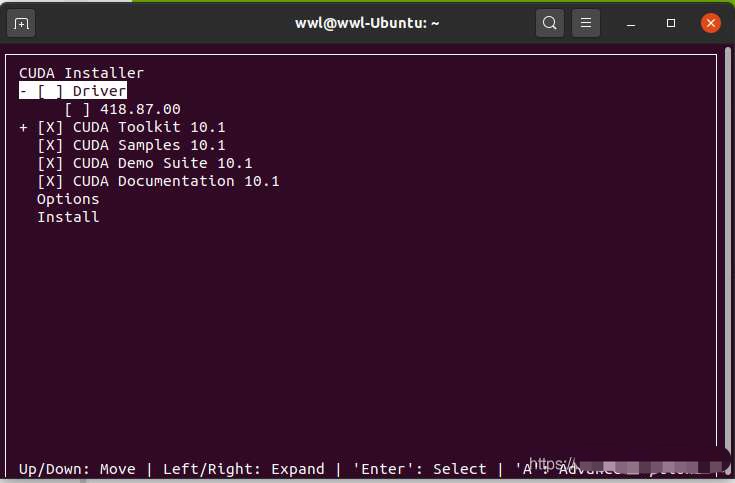
到这一步时注意,因为我们已经有安装了驱动,所以这里使用空格选中driver,取消驱动安装。然后移动最下面install,回车进行安装。
安装好后,可发现有了/usr/local/cuda-10.1这个文件夹,也就是安装路径所在。根据安装完成的提示,需要进行相关路径配置。在~/.bashrc中进行添加即可
安装cudnn
下载cudnn。登录下载与cuda10.1对应的cudnn 7.6.5,选择cudnn library for linux。下载好后进行解压,将解压的 cuda/include/cudnn.h 复制到 /usr/local/cuda/include,cuda/lib64/下所有文件复制到 /usr/local/cuda/lib64 下,并为这些文件添加读取和执行权限:
sudo chmod 755 /usr/local/cuda/include/cudnn.h /usr/local/cuda/lib64/libcudnn*android 添加模块并使用JNI调用c++
首先新建一个模块,比如Android Library。在该模块的java类中,首先载入c++的共享库,语句如下:
static{
System.loadLibrary("libname");
}
//libname就是下面要建立的cpp文件的名称
后面声明使用JNI的java方法,比如
public native String stringFromJNI();
其中的native不可省略
完成后在该模块下src/main目录下新建cpp文件夹, 然后在cpp文件夹下新建cpp文件(文件名要与java类中载入共享库的名称相同),实现该JNI方法。所对应的c++函数名形式为:
#include <jni.h> //必要语句 extern "C" JNIEXPORT jstring JNICALL Java_包名_类名_方法名(JNIEnv *env) 注:一般在写的时候AS会给出提示,建议直接使用提示生成。
cpp文件写完后, 再在该文件夹下新建CMakelists.txt文件。内容如下:
# For more information about using CMake with Android Studio, read the
# documentation: https://d.android.com/studio/projects/add-native-code.html
# Sets the minimum version of CMake required to build the native library.
cmake_minimum_required(VERSION 3.4.1)
# Creates and names a library, sets it as either STATIC
# or SHARED, and provides the relative paths to its source code.
# You can define multiple libraries, and CMake builds them for you.
# Gradle automatically packages shared libraries with your APK.
add_library( # Sets the name of the library.
libname
# Sets the library as a shared library.
SHARED
# Provides a relative path to your source file(s).
src/main/cpp/libname.cpp)
# Searches for a specified prebuilt library and stores the path as a
# variable. Because CMake includes system libraries in the search path by
# default, you only need to specify the name of the public NDK library
# you want to add. CMake verifies that the library exists before
# completing its build.
find_library( # Sets the name of the path variable.
log-lib
# Specifies the name of the NDK library that
# you want CMake to locate.
log )
# Specifies libraries CMake should link to your target library. You
# can link multiple libraries, such as libraries you define in this
# build script, prebuilt third-party libraries, or system libraries.
target_link_libraries( # Specifies the target library.
libname
# Links the target library to the log library
# included in the NDK.
${log-lib} )
然后再在该模块下的build.gradle中添加对c++的编译配置信息。在defaultConfig节点下,添加
externalNativeBuild {
cmake {
cppFlags "-fexceptions"
arguments "-DANDROID_STL=c++_shared"
}
ndk{
abiFilters 'armeabi-v7a', 'arm64-v8a' ,'x86'
}
}
作用是配置为共享库,与设置目标平台。接着再将CMakeLists.txt关联到模块,在android节点下添加
externalNativeBuild {
cmake {
path "src/main/cpp/CMakeLists.txt"
}
}
至此模块的任务算是完成了。可以在其它模块中引入该模块使用。引入方式为:
import 该模块包名.模块类名;
另外要在其模块的build.gradle中,dependencies节点中,添加
implementation project(‘:模块名’)
docker 常用命令
载入镜像启动容器
docker run -it image-name:tag
载入镜像启动容器(启用GPU)
docker run -it –gpus all image-name:tag
查看容器运行情况
docker ps -a
停止运行的容器
docker stop containerid
停止所有运行的容器
docker stop $(docker ps -a -q) 括号中的命令是查看所有容器ID
重启容器
docker restart containerid
进入容器
docker attach containerid \ docker exec -it containerid /bin/bash
重启并进入容器
docker start -i containerid
端口、目录映射
docker run -p 主机端口:容器端口 image:tag
docker run -it -v 主机目录:容器目录 image:tag 注:目录必须是绝对路径
设置共享内存容量
docker run … –shm-size 8G
在容器中运行程序报nccl错误,可以在启动容器时加上–ipc=host参数
查看容器运行情况
docker ps -a
停止运行的容器
docker stop containerid
停止所有运行的容器
docker stop $(docker ps -a -q) 括号中的命令是查看所有容器ID
重启容器
docker restart containerid
进入容器
docker attach containerid \ docker exec -it containerid /bin/bash
重启并进入容器
docker start -i containerid
删除容器
docker rm containerid
删除所有容器
docker rm $(docker ps -a -q)
查看镜像
docker images
删除镜像(需要先停止并删除使用该镜像运行的容器)
docker rmi imageid (加上 -f 可以强制删除)
将容器保存为镜像
docker commit -a ‘修改作者’ -m ‘描述’ containerID image-name:new-tag
将镜像打包为tar文件
docker save -o xxx.tar image-name:tag
从打包文件提取镜像
docker load -i xxx.tar
提取之后镜像会保存到本地,就可以运行该镜像了
将容器打包为tar文件
docker export -o xxx.tar container-name
将export打包的文件提取出镜像
docker import xxx.tar image-name:tag 注:这里image-name:tag是自己取的
docker save和export的区别
docker save会保存镜像的历史记录,而export不会保存。export仅保存容器当前的状态
压缩镜像大小
pip install docker-squash
docker-squash image:old -t image:new
ubuntu 通过xrdp建立远程桌面连接
首先安装桌面环境用于远程桌面。xfce是一个比较合适的桌面环境。
按照下面链接的步骤安装桌面环境与xrdp
https://www.itcoder.tech/posts/how-to-install-xrdp-on-ubuntu-18-04/
安装完成后,发现连接远程后,输入账号密码后会蓝屏,用下面链接的方法解决。安装非官方的xrdp,可能官方的xrdp是有问题的
https://askubuntu.com/questions/1166568/remote-desktop-blue-screen-after-login
sudo add-apt-repository ppa:martinx/xrdp-hwe-18.04 sudo apt-get update sudo apt-get install xrdp xorgxrdp